This was a self-directed deep learning project I built to explore NLP and transformer fine-tuning. The goal was to train a model that could classify online comments across six toxicity categories — toxic, severe toxic, obscene, threat, insult, and identity hate — and then compare two different approaches to fine-tuning: a straightforward baseline and a more deliberate custom architecture.
I trained both models on the Jigsaw Toxic Comment Classification Challenge dataset, built a FastAPI inference backend, and wrapped everything in a SvelteKit web app where you can type in any text and see predictions from both models side-by-side in real time.
The Problem and Dataset
Online toxicity is a multi-label classification problem, meaning a single comment can belong to several categories at once. A comment can be both obscene and an insult, for example. This makes it more nuanced than a binary "toxic or not" problem, the model needs to independently assess each category instead of just picking one.
The dataset I used was the Jigsaw Toxic Comment Classification Challenge dataset, which contains over 150,000 Wikipedia comments labelled by human raters across the six categories. The data is heavily imbalanced, most comments are non-toxic, which influenced some of the design choices made for the custom model later on.
Model Architecture
Both models are built on top of distilroberta-base, a distilled version of RoBERTa that keeps most of the performance of the full model at significantly lower compute cost. This was nessecary as I only had a single RTX 4070 Super GPU. The two models differ in how they use the transformer's output to make predictions.
Standard Baseline Model
The first model is the simplest possible approach. The pretrained DistilRoBERTa encoder is loaded with a classification head on top. The [CLS] token from the final hidden layer, which RoBERTa trains to summarize the sequence, is passed through a linear layer to get the logits for each of the six labels. It's trained end-to-end with binary cross-entropy loss and sigmoid activations.
This model essentially delegates all the work to the pretrained encoder and keeps fine-tuning as minimal as possible.
Custom Attention Pooling Model
The second model takes a more designed approach at the classification stage. Instead of relying solely on the [CLS] token, I replaced the standard pooling with a learned attention pooling mechanism. A small linear projection computes a scalar attention score for each token, and then applies softmax to generate a weighted average of all token hidden states. The is beecause different words contribute differently to toxicity. A curse word is much more toxic than the context around it. The model should learn to focus on the most relevant tokens rather than treating every token uniformly.
The pooled representation is then passed through a custom classification head that includes layer normalization, a dense projection with GELU activation, a residual connection, dropout, and a final output layer.
``` hidden_states (batch, seq_len, 768) ↓
attention scores per token → softmax → weights ↓
weighted sum → pooled vector (batch, 768) ```
``` pooled vector ↓
LayerNorm → Dense (768→768) → GELU ↓ + residual
Dropout → Dense (768→6) → logits ```
The other key difference is the loss function. Instead of standard binary cross-entropy, the custom model uses focal loss, which down-weights easy examples and focuses the gradient on harder, underrepresented ones. This was my attempt to fix the class imbalance in the dataset where most comments are clean.
Training Setup
Both models were trained under the same conditions using the HuggingFace Trainer API:
| Hyperparameter | Value |
|---|---|
| Base model | distilroberta-base |
| Batch size | 16 |
| Epochs | 3 |
| Learning rate | 2e-5 |
| Weight decay | 0.01 |
| Max sequence length | 128 tokens |
| Train/eval split | 90% / 10% |
GPU acceleration with fp16 mixed precision was used when available. The evaluation metric used was macro F1 across all six labels.
Results and Comparison
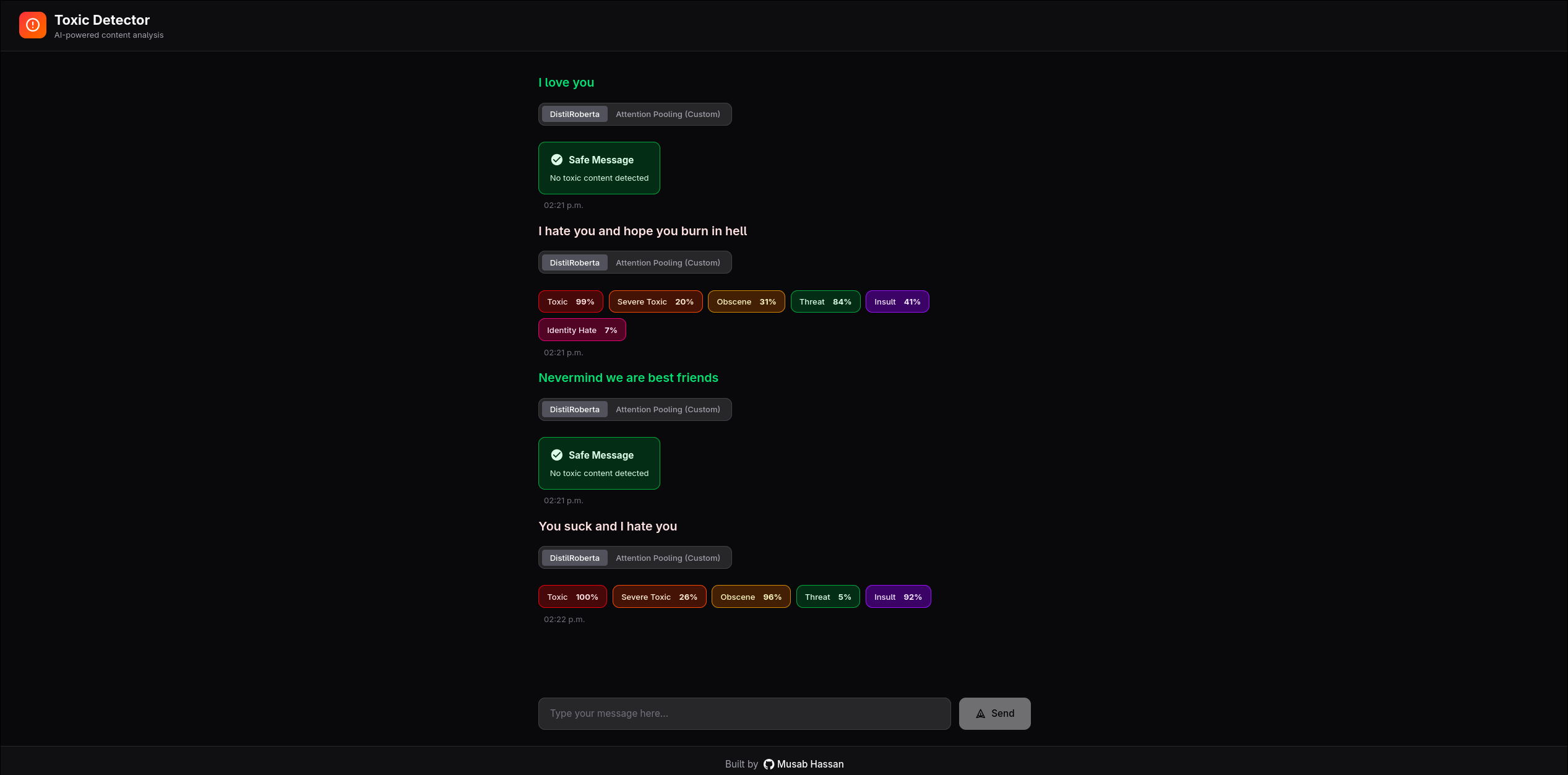
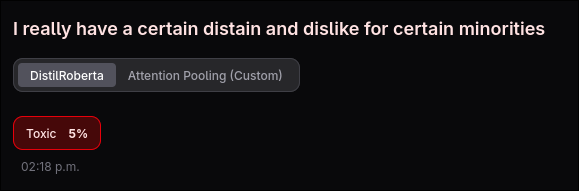
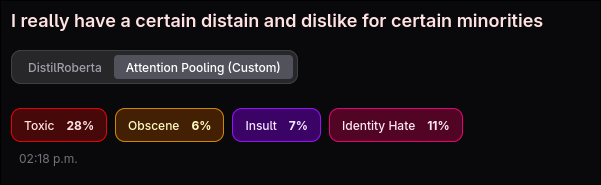
After training, both models were evaluated on the test split. The custom model with attention pooling and focal loss showed improved performance on the minority categories (threat, severe toxic, identity hate) compared to the standard baseline, which is exactly what I had hoped to see with. The standard model performed well on the dominant categories but was less sensitive to rare but severe cases.
To make the comparison intuitive, I built a web app to interface with the models so you can enter any text and see confidence scores from both models simultaneously.
Web App and API
The web app has a SvelteKit frontend styled with Tailwind CSS and shadcn/ui components. Each toxicity category is colour-coded, and results are displayed as labelled confidence bars below each submitted comment. Messages persist in a chat-style history so the user can experiment and compare multiple inputs side-by-side.
The inference layer that the frontend interfaces with is a FastAPI server that loads both models on startup and runs them in parallel on each POST request. The tokenization, inference, and sigmoid conversion all happen server-side, and the API returns a JSON object with confidence scores for each label from each model.
Reflection
This project was my first real end-to-end NLP system, and it taught me that fine-tuning actually involves more than just running Trainer.train(). Designing the custom architecture forced me to think about what the model is actually doing with the transformer output, why pooling strategy matters, how the classifier head interacts with the encoded representations, and what focal loss is actually doing mathematically to the gradient.
The class imbalance problem was also a useful lesson. I noticed early on that the standard model was ignoring the rarest categories, and debugging that led me down the path of focal loss and attention pooling, neither of which I would have explored if the problem had been clean and balanced.
Building the full stack around the model, from training notebook through to a proper frontend, also helped me see the gap between a model that works in a notebook and one that's actually usable. Getting the API and frontend to feel responsive and clear took even more effort than making the model itself.